Руководитель группы нейросетевых технологий поиска Яндекса, Александр Готманов, рассказал на хабре о внедрении новой нейросетевой архитектуры для ранжирования страниц. Сами разработчики называют архитектуру «трансформером».
Основной критерий релевантности выдачи — связь между запросом пользователя и документом на странице. Чтобы грамотно ранжировать страницы, необходимо научиться оценивать смысловую связь между ними. Если в случае с самим пользователем связь строится очевидно, то для алгоритма это уже серьезная задача.
Как было раньше
Алгоритм можно настроить на число совпадающих символов в запросе и документе, это самый простой вариант. Можно использовать уже существующую историю по аналогичному запросу и взять оттуда статистику о том, какие документы получили больше всего кликов, а какие меньше. Такой расчет дает нам полезную информацию для семантической связи, но не дает смысловое понимание текста. Зато у пользователя складывается полное ощущение, будто поиск его понимает. Яндекс работал по такому принципу до 2016 года.
Как это сейчас
За эти годы Яндекс придумал и использовал несколько десятков эффективных эвристических (приблизительно точных) алгоритмов. Для наглядности, Александр приводит в качестве примера один из наиболее простых:
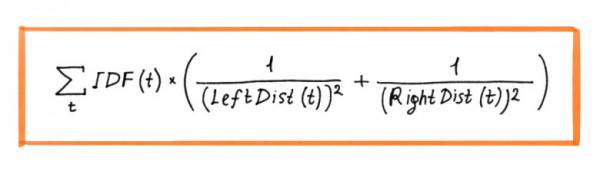
В этом алгоритме каждому «хиту» (вхождение слова из запроса в документ, от англ. hit, попадание) t присваивается значимость в зависимости от частотности слова и расстояния до ближайших вхождений других слов в документе. Полученные значения суммируются по всем хитам. Такой подход помогал накапливать смысловую связь, и внедрения за полгода-год заметно влияли на ранжирование.
Другим эффективным методом стало расширение запроса благодаря синонимичным словам. Либо же использование иной формулировки со схожим смыслом. Плюс данного метода в том, что при нахождении похожего запроса его можно применить сразу же во всех алгоритмах. В результате многолетней практики у Яндекса накопилось тысячи сигналов ранжирования, и все они подаются на вход по одной итоговой модели. Для ее обучения Яндекс использует открытую реализацию алгоритма GBDT — CatBoost.
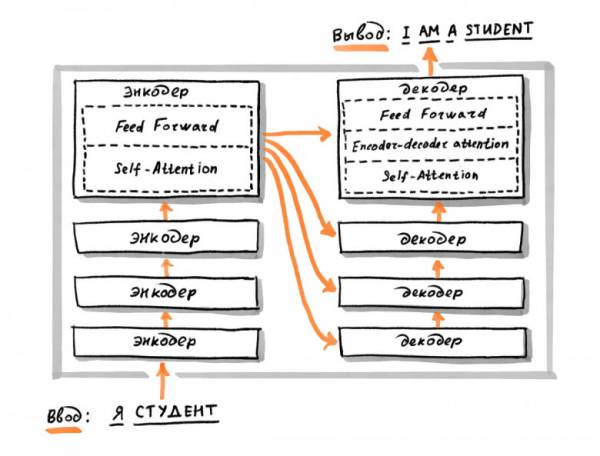
В сетях с архитектурой трансформеров каждый элемент текста обрабатывается по отдельности и представляется отдельным вектором. Элементом может быть символ, слово или частотная последовательность символов (например, BPE-токен). Сеть использует механизм «внимания» для того, чтобы концентрироваться на участках текста во время вычислений.
С помощью этой архитектуры нейросеть может выделить лишь часть документа с релевантной для пользователя информацией. Например, при поиске кофеварки сеть выделит именно ту часть документа, в которой говорится о ней. Ранжирование остальных частей будет учитываться меньше. Трансформеры также легко обучаются генерации естественных текстов и переводам, поскольку часто используются для ответов на вопросы.
Глубокие нейронные сети, которые используются теперь в Поиске Яндекса, требуют миллиардов примеров для обучения. Для каждого из примеров собрать такое количество практически невозможно, это требует огромного вложения времени и денег. Для решения этой задачи на помощь приходит подход transfer learning. Суть заключается в том, чтобы переиспользовать информацию, накопленную в рамках одной конкретной задачи, для других задач.
Сперва Яндекс хотел применить для своих задач проект BERT от Google, находящийся в открытом доступе. Но оказалось, что простое дообучение к уже готовой модели не приносит необходимых результатов. В результате разработчикам пришлось заняться своей собственной архитектурой с нуля. Самое сложное — собрать необходимую вычислительную мощность. По расчетам, для работы нейросети необходимо 100 одновременно работающих ускорителей.
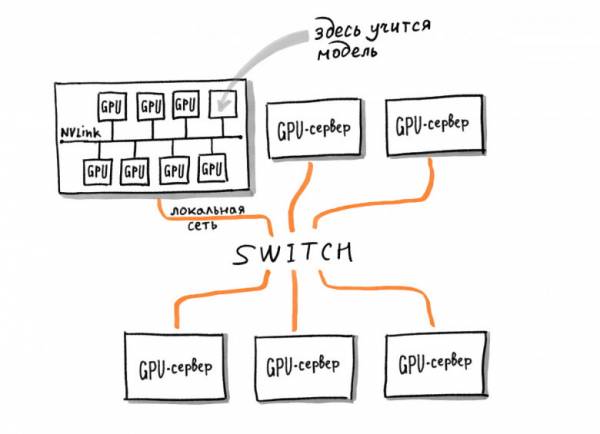
В результате у Яндекса получилось создать свою собственную самообучающуюся тяжелую модель нейросети, адаптированную под задачи поисковой системы. Это внедрение принесло рекордные улучшения в ранжировании за последние 10 лет. Для сравнения, если отключить все упомянутые выше сигналы ранжирования, которые исчисляются тысячами и оставить только новую модель, качество ранжирования упадет всего на 4-5%. По словам Александра, данный подход может добавить пользователям ощущения поиска по смыслу чаще, чем когда-либо.

Автор:
Илья Боровец
Теги поста или какие разделы почитать еще:
Источник: pr-cy.ru







