
Автор – Дэйв Дэвис (Dave Davies), основатель Beanstalk Internet Marketing
Работая в области SEO, важно понимать ту систему, для которой вы проводите оптимизацию. В частности, нужно знать:
- Как поисковые системы сканируют и индексируют сайты;
- Как функционируют алгоритмы поиска;
- Как поисковые системы используют намерение пользователя в качестве сигнала для ранжирования.
Ещё одной важнейшей областью для понимания сегодня является машинное обучение. В последнее время о machine learning (ML) слышно всё чаще, но как же оно влияет на поиск и SEO на самом деле?
В этой статье мы рассмотрим всё, что вам нужно знать о том, как поисковые системы используют эту технологию.
Что такое машинное обучение?

Понять, как машинное обучение используется в работе поисковых систем, будет сложно без знания о том, чем же оно является. Поэтому, прежде чем перейти к практическим вопросам, давайте начнём с основ.
Согласно определению Стэнфордского университета, «машинное обучение – это наука о том, как заставить компьютеры действовать, не используя чётких детерминированных алгоритмов».
Маленькое отступление, прежде чем мы продолжим
Машинное обучение – это не то же самое, что и искусственный интеллект (ИИ), но в их применении эта грань начинает размываться.
Как отмечалось выше, машинное обучение – это наука о том, как заставить компьютеры делать выводы, основанные на определённой информации, не программируя их на конкретный алгоритм выполнения заданной задачи.
ИИ, с другой стороны, – это наука о создании систем, которые имеют человекоподобный разум и похожим образом обрабатывают информацию.
Другими словами, машинное обучение – это система, разработанная для решения проблемы. Для выработки решения она работает математическим путём. При этом решение может быть специально запрограммировано или же разработано человеком в ручном режиме.
Эту же работу могут выполнить несколько сотен математиков, но тогда она займёт несколько лет (поскольку обычно речь идёт об очень обширном массиве данных) – при условии, что никто из них не допустит ни одной ошибки. Машинное обучение позволяет выполнять такие задачи намного быстрее.
Если говорить об искусственном интеллекте, то эти системы более креативны и, как результат, менее предсказуемы.
Нейросеть, которой поставлена та же задача, может не анализировать весь массив данных, чтобы прийти к каким-то выводам, а использовать выводы из предыдущих исследований. Или же добавить в набор новые данные. Или же начать разрабатывать новую систему, предшествующую первоначальной задаче.
Ключевое слово здесь – интеллект. Хоть и искусственный, но он также создаёт переменные и определяет неизвестные области подобно тому, как это делает человек, общаясь с другими людьми.
Возвращаясь к машинному обучению и поисковым системам
Прямо сейчас то, что поисковые системы (и большинство учёных) активно развивают, – это машинное обучение.
У Google есть бесплатный курс и целый портал, посвящённый обучению и работе с ML, компания также открыла исходный код своего фреймворка TensorFlow и активно инвестирует в аппаратное обеспечение для управления ИИ.
За машинным обучением будущее, поэтому о нём важно знать.
Хотя мы не можем перечислить (и даже знать) все случаи применения машинного обучения в Googleplex, давайте всё же рассмотрим несколько известных примеров.
RankBrain
По сути, эта система оснащена только пониманием сущностей (вещь или концепция, которая является единственной, уникальной, чётко определённой и различимой) и перед ней поставлена задача выработать представление о том, как эти сущности соединяются в запросе, чтобы улучшить их понимание и набор известных ответов. Это очень упрощённое описание и сущностей, и RankBrain, но для целей данной статьи оно является вполне достаточным.
Итак, Google дал этой системе некоторые данные (запросы) и, возможно, набор известных сущностей. Что было далее, достоверно неизвестно, но по логике, затем система самостоятельно обучалась на этом наборе запросов тому, как распознавать неизвестные сущности, с которыми она сталкивалась. (Данная система была бы бесполезной, если бы она не могла понимать новые названия, даты и т.п.).
После того, как система завершила этот процесс и начала выдавать удовлетворительные результаты, ей, вероятно, была поставлена задача обучиться пониманию связей между сущностями и того, какие данные подразумеваются или запрашиваются напрямую, а также искать соответствующие результаты в индексе.
Эта система решает множество проблем, с которыми сталкивается Google.
RankBrain использует машинное обучение для того, чтобы:
- Непрерывно узнавать о связанности сущностей и отношениях между ними;
- Понимать, когда слова являются синонимами, а когда – нет;
- Инструктировать другие части алгоритма о том, как генерировать правильную SERP.
В своей первой итерации RankBrain тестировался на запросах, с которыми Google не встречался ранее.
Если RankBrain способен улучшать результаты по запросам, по которым, скорее всего, не проводилась оптимизация, и использовать при этом комбинацию из старых и новых сущностей, чтобы предоставить пользователям те результаты, которые им нужны, то эта система должна была быть внедрена по всему миру. И это было сделано в 2016 году.
Давайте посмотрим на следующие два варианта запросов. Несмотря на небольшие различия, по сути, в поисковой выдаче мы видим одни и те же результаты:
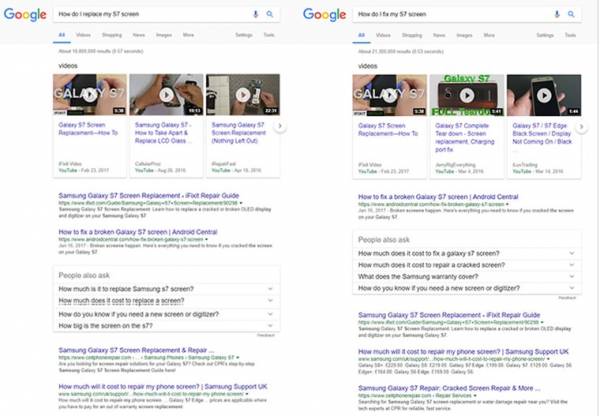
Теперь давайте посмотрим на ещё один пример:
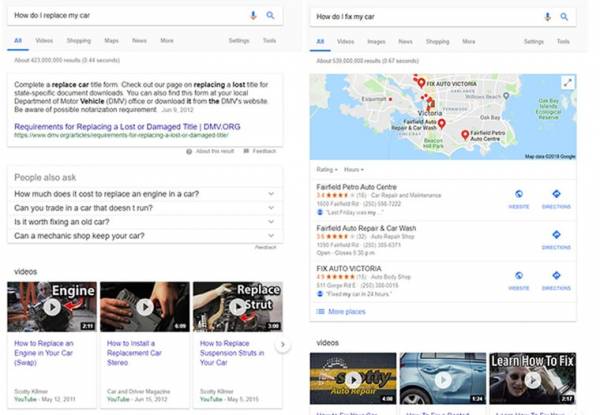
Машинное обучение помогает Google не только видеть сходства в запросах, но и понимать, что если пользователь хочет починить машину (how do I fix me car), то ему нужен механик, тогда как для ремонта (how do I replace my car) ему нужна информация о запчастях.
На этом примере мы видим машинное обучение в действии при определении намерения, стоящего за запросом, макета SERP и действий, которые нужны для реализации намерения.
Обратите внимание, что это не только RankBrain, но и машинное обучение.
Спам
Если вы используете Gmail или другой почтовый клиент, вы также видите машинное обучение в работе.
Согласно Google, в настоящее время Gmail блокирует 99,9% спама и фишинговых сообщений с коэффициентом ошибки на уровне 0,05%.
Они делают это, используя ту же основную технологию – дают ML-системе некоторые данные и запускают обучение.
Когда эта работа производилась вручную, то блокировалось 97% спама при коэффициенте ошибки на уровне 1% (это значит, что 1% реальных писем попадал в папку нежелательных сообщений).
Дайте системе машинного обучения все подтверждённые спам-сообщения, позвольте ей построить модель на основе тех общих черт, которые они имеют, добавьте новые сообщения, установите награду за успешное нахождение спама и через какое-то время (не очень долгое) она изучит ещё больше сигналов и будет реагировать в разы быстрее, чем человек.
Итак, как машинное обучение работает?
В этой статье мы обещали дать объяснение машинному обучению, а не только привести список примеров. Хотя эти примеры были необходимы, чтобы проиллюстрировать довольно лёгкую для понимания модель. Однако это не значит, что эту систему так же легко построить.
Общая модель машинного обучения следует приведённой ниже схеме:
- Дайте системе набор известных данных, то есть массив данных с большим количеством возможных переменных, связанных с известным положительным или отрицательным результатом. Эти данные будут использоваться для обучения системы и чтобы дать ей отправную точку. В итоге она поймёт, как распознавать и взвешивать факторы, основанные на прошлых данных, для получения положительного результата.
- Установите награду за успех. Когда система обучится на известных данных, дайте ей новые данные без известного положительного или отрицательного результата. Система не знает о связях новой сущности, а также о том, является письмо спамом или нет. Когда она будет выбирать правильный вариант, то будет получать вознаграждение. Например, балл. Тогда каждый правильный ответ будет добавляться к общей сумме баллов при заданной максимальной цели.
- Как только показатели успеха станут достаточно высокими для того, чтобы превзойти существующие системы или другой порог, система машинного обучения может быть интегрирована с алгоритмом в целом.
Эта модель называется контролируемым обучением, и, если моя догадка верна, то это модель, используемая в большинстве реализаций алгоритма Google.
Ещё одной моделью машинного обучения является неконтролируемое обучение. Это подход, который используется для группировки похожих историй в Новостях Google. Также можно предположить, что эта модель используется для идентификации и группировки изображений в Google Картинках.
В этой модели системе не сказано, что она ищет, а просто поручается группировать объекты (изображения, статьи и т. д.) в группы по сходным признакам (сущности, которые они содержат, ключевые слова, связи, авторы и т. п.).
Почему это важно?
Знание о том, что представляет собой машинное обучение, будет иметь решающее значение, если вы попытаетесь понять, как формируется SERP, и почему страницы ранжируются на тех или иных позициях.
Знать алгоритмические факторы ранжирования важно, но не менее значимо понимать ту систему, в которой они используются.
Уделяйте внимание тем типам контента, которые, по мнению Google, могут удовлетворить потребность пользователя (текстовые публикации, изображения, новости, видео, товарные результаты, блоки с ответами и т.п.) и работайте над тем, чтобы их предоставлять.
Источник: searchengines.ru







