- Основные возможности Парсера Wordstat в PromoPult:
- Немного теории: зачем знать частотности ключевиков?
- Как узнать частотности с помощью PromoPult
- Этап №1. Загрузка ключевых фраз
- Этап №2. Выбор региона
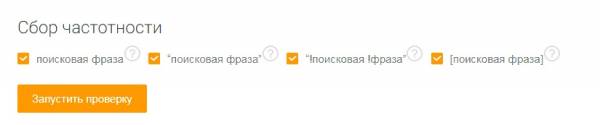
- Этап №3. Указание параметров сбора частотностей
- Этап №4. Получение результата
- Сколько стоит инструмент
- Работа с Парсером Wordstat: помните о сезонности
- Подводим итоги
Узнать частотности Wordstat можно вручную, но это долго и неудобно. Для ускорения работы есть парсеры: десктопные программы, расширения для браузеров, облачные сервисы и скрипты. Все они похожи — есть лишь отличия в нюансах работы. Собственный сервис есть и в системе PromoPult. Разбираемся, как он работает и чем он лучше аналогов.
Основные возможности Парсера Wordstat в PromoPult:
- массовая проверка частотностей из левой колонки Wordstat для указанных фраз;
- загрузка фраз списком или с помощью файла XLSX;
- возможность парсить частотность в любом регионе Яндекса;
- учет типа соответствия при парсинге (операторы «фраза», «!фраза» и [фраза]);
- сохранение всех отчетов «в облаке».
Особенности сервиса:
- неограниченное количество поисковых запросов при проверке за один раз;
- сбор частотностей онлайн — не нужно устанавливать софт;
- не нужно создавать фейковые аккаунты в Яндексе специально для парсинга или рисковать собственными аккаунтами;
- не нужно использовать прокси-серверы и вводить капчу;
- суммирование в отчете частотностей по указанным регионам или разбивка по каждому региону;
- высокая скорость парсинга;
- удобный для последующей обработки отчет в формате XLSX.
Немного теории: зачем знать частотности ключевиков?
Основная причина, по которой собирают частотности, — прогнозирование трафика. Зная, сколько раз пользователи интересовались определенной фразой, можно примерно рассчитать, сколько сайт получит переходов, если займет N-ую позицию в поиске.
Как это работает на практике:
1. Вы сформировали список ключевых фраз, по которым планируете продвигаться.
2. Для фразы, по которой планируете оценить трафик, определяете частотность (например, «купить тахту в Москве» — 2852).
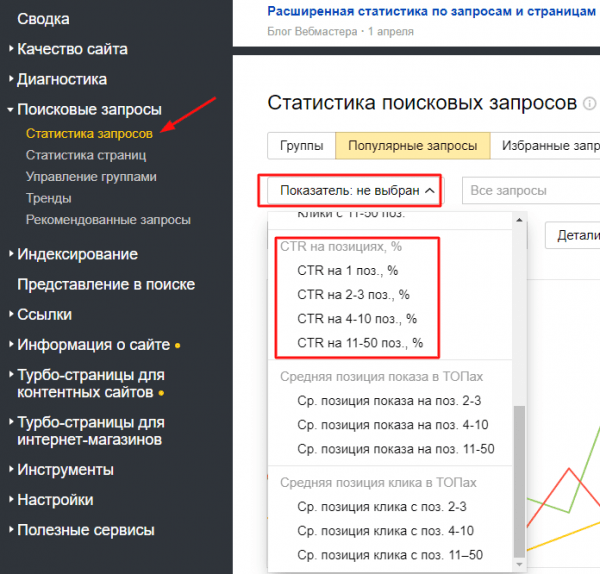
3. Узнаете значения CTR в зависимости от позиции в поиске. Приблизительные данные о распределении CTR можно найти в открытых источниках, но если у вас сайт работает хотя бы несколько месяцев, то более точные данные доступны в отчете Яндекс.Вебмастера «Поисковые запросы» / «Статистика запросов». В нем нужен показатель: «CTR на позициях, %»:
4. Составляете прогноз трафика для ТОП-10. Для этого умножаете частотность на CTR и делите на 100 %.
Допустим, если CTR 2-3 позиции составляет 25 %, то прогнозный трафик при достижении этой позиции равен: 2852*25/100 = 713.
Вторая причина собирать частотности — отсеивание «мусорных» фраз. Это фразы, частотность которых стремится к нулю, и их нет смысла включать на существующие страницы (и тем более создавать под них новые страницы).
Читайте также:
Как почистить семантическое ядро от дублей и мусора
Какие именно фразы считать «мусорными»? Здесь все зависит от тематики. Например, если тематика узкая, трафика мало (например, по ключам «покупка аппарата МРТ» или «ремонт Vertu»), и каждый пользователь на вес золота, то можно оставлять и фразы с частотностью 1. Для магазинов масс-маркета отсеивают запросы с частотностью ниже 5. А для информационных сайтов частотность 10-20 вполне может быть нижним пределом. Главное, не переусердствуйте с удалением лишних фраз, иначе есть риск потерять трафик по низкочастотным запросам, который порой составляет до 70-80 % от общего трафика.
Еще одна причина уточнить частотности — выстраивание иерархии запросов на странице. Более частотные запросы добавляют в Title и H1, а под менее частотные — формируют разделы и подразделы.
Продвигать сайт на автомате? С модулем SEO от PromoPult это реально! Внутренняя оптимизация, линкбилдинг, наполнение контентом — все это автоматизируется в пару кликов. Вам лишь остается контролировать результат. Готовы? Поехали!
Как узнать частотности с помощью PromoPult
Этап №1. Загрузка ключевых фраз
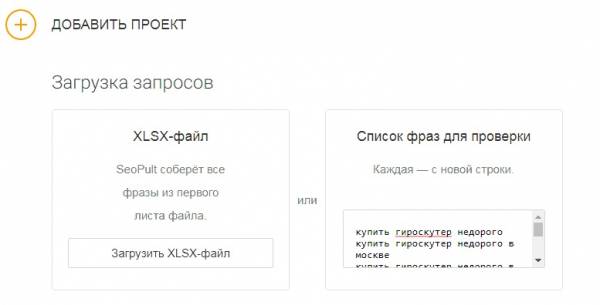
Для начала перейдите на страницу Парсера и загрузите запросы, частотности которых необходимо узнать. Сделать это можно двумя способами:
- С помощью XLSX-файла. PromoPult учитывает все фразы из первого листа файла. Система считывает все ячейки вне зависимости от их расположения на листе по принципу «одна ячейка — один ключ». Поэтому будьте внимательны при заполнении листа, чтобы в ячейках не было вспомогательной информации — названий столбцов, пояснений, нумерации и т. п., иначе вы потратите лишние деньги.
- Списком — просто скопируйте все запросы и вставьте их в поле. При этом каждая новая фраза должна идти с новой строки.
Этап №2. Выбор региона
В системе доступны все регионы, которые поддерживает Яндекс. Выбор регионов для парсинга зависит от поставленных задач. Рассмотрим несколько ситуаций:
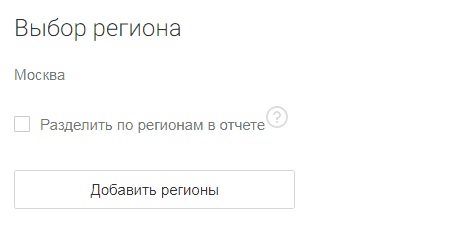
- Вы планируете продвигаться в одном регионе. Это ситуация, характерная для информационных сайтов, небольших региональных интернет-магазинов и локальных компаний, оказывающих услуги. Просто укажите нужный регион (опцию «Разделить по регионам в отчете» НЕ активируйте).
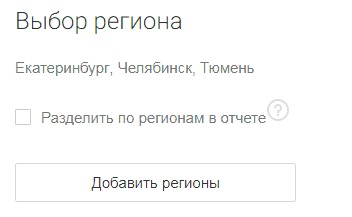
- Вы планируете продвигаться в основном и нескольких близлежащих регионах. Ситуация характерна для региональных компаний и интернет-магазинов (без поддоменов), которые в силу территориальной близости будут продвигаться в своем и прилегающих регионах. В этом случае выберите регионы (опцию «Разделить по регионам в отчете» НЕ активируйте). Частотности по всем выбранным регионам будут суммироваться в одном отчете.
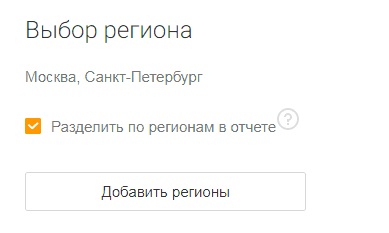
- Вы планируете создавать региональные поддомены и продвигаться в разных регионах. Ситуация характерна для крупных интернет-магазинов или онлайн-сервисов (например, такси, служб доставки еды и т. п.). В этом случае выберите нужные регионы и активируйте опцию «Разделить по регионам в отчете». В отчете на отдельных листах будут представлены отчетности по каждому заданному региону. То есть фактически вы получаете не один отчет, а столько, сколько регионов укажете.
Хотите расширить базовое семантическое ядро? Вот инструкция как это сделать с помощью фраз-ассоциаций.
Этап №3. Указание параметров сбора частотностей
Если в Вордстате просто ввести фразу и запустить сбор частотностей, то вы получите статистику по всем вариантам словоформ (в том числе по фразам, которые включают заданную). Это так называемое широкое соответствие. Например, 12902 показов по фразе «купить гироскутер недорого» не означает, что пользователи 12902 раз вводили эту фразу в таком варианте написания. В эту цифру входят и обращения по фразе «гироскутер купить в Москве недорого», и «куплю гироскутер рублями недорого», и «гироскутер купить в Перми недорого» и мн. др.
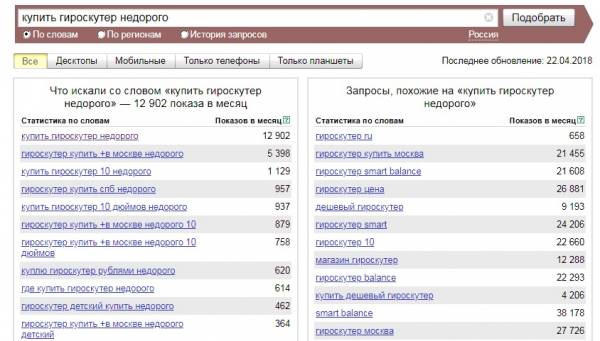
Для получения более точной статистики по запросам используются операторы соответствия. О них мы подробно рассказывали в этой статье. Здесь остановимся на тех из них, которые поддерживает инструмент парсинга Wordstat от PromoPult.
1. Широкое соответствие (информация ищется по заданным фразам без дополнительных операторов). В этом случае вы получаете очень широкую статистику, далеко не всегда релевантную и отражающую реальную картину спроса. На это есть несколько причин:
- ложная статистика (в сети работает масса парсеров, которые создают ложные обращения к Яндексу, из-за чего полученные цифры слишком завышены);
- нерелевантная семантика (например, по запросу «купить памперс» люди необязательно ищут средства детской гигиены — «памперсом» называют поглотители чернил для принтеров, и такие запросы довольно популярны).
Парсить частотности в широком соответствии полезно лишь с точки зрения общей картины, для понимания тенденций, но для принятия окончательных решений по включению тех или иных запросов в ядро лучше воспользоваться представленными ниже операторами соответствия.
2. Фиксация количества слов (оператор «кавычки»). В этом случае отражается статистика только по заданной фразе, но с учетом различных падежей и перестановки слов. Например, частотность ключа «купить гироскутер недорого» включает частотность фразы «недорого купить гироскутеры», но не включает «купить гироскутер недорого в Москве» или «купить гироскутер». Это намного более точная статистика, чем при широком соответствии, поскольку отражает информацию по конкретному запросу.
3. Фиксация количества слов + морфологии (оператор «!кавычки с !восклицательным !знаком»). Если вы хотите получить информацию по конкретному запросу с заданной словоформой, используйте этот оператор. Если задать «!купить !гироскутер !недорого», то вы получите информацию только по такой словоформе (например, статистика по запросу «купить гироскутеры недорого» включена не будет). Важно понимать, что если семантика узкая, то цифры получатся слишком заниженными (или вовсе будут нули). Поэтому этот оператор больше подходит для популярных тематик, где нужно найти наиболее востребованные варианты написания ключевых запросов.
4. Фиксация порядка слов (оператор [квадратные скобки]). Этот оператор используется, если для правильной оптимизации страниц важен порядок слов. Классический пример — с покупкой билетов. По фразе «билеты Москва Питер» в широком соответствии будет включена статистика по фразам вроде «билеты Питер Москва», которые подходят для оптимизации страницы поиска билетов из Москвы в Санкт-Петербург. Чтобы этого избежать, искомая фраза берется в квадратные скобки, и тогда статистика будет только по фразам с заданным порядком слов (с учетом разной морфологии).
Лучше всего собирать частотности с учетом всех операторов соответствия. Так у вас будет наиболее полная картина. Если же у вас бюджет ограничен, активируйте хотя бы два типа соответствия — например, широкое и «кавычки».
Обогатить семантическое ядро? Легко! В статье Как быстро собрать поисковые подсказки из Яндекса, Google и Youtube описано, как сделать это без лишних трудозатрат.
Этап №4. Получение результата
Время сбора частотностей зависит от количества запросов, регионов и типов соответствия. Если запросов не очень много (до 1000), процесс займет не более 1-2 минут. Результат доступен в «Списке задач»:
Для скачивания отчета необходимо кликнуть по соответствующей ссылке. В отчете вы увидите список заданных фраз и частотности напротив каждой из них. Если вы задавали разделение по регионам, то в отчете будет несколько листов, соответствующих каждому региону. Также в каждом отчете есть лист с исходными настройками.
Если у вас нет времени ждать окончания выполнения задачи, вы можете закрыть браузер — парсинг будет идти без вашего участия.
После завершения парсинга система уведомит вас на электронную почту, указанную при регистрации в PromoPult. Отчеты доступны в системе в любое время, поэтому их необязательно скачивать сразу по окончании парсинга.
Если вы по ошибке зададите повторный парсинг с аналогичными исходными данными, то система уведомит вас об этом. Это позволяет избежать лишней траты денег.
После сбора ключей и оценки частотностей запросы необходимо сгруппировать. Лучший способ сделать это — кластеризовать. Вот подробный гайд, который поможет вам в этом.
Сколько стоит инструмент
Для тарификации используется базовая единица — ТЗ (получение данных по одному типу частотности по одной фразе для одного набора регионов).
Если вы указываете несколько регионов, но не активируете опцию «Разделить по регионам в отчете», то количество регионов не влияет на конечную стоимость проверки. Если же вы хотите получить раздельные отчеты по указанным регионам, то стоимость будет увеличиваться пропорционально количеству регионов.
Стоимость формируется по кумулятивному принципу: за первую 1000 ТЗ вы платите по 0,07 руб. за ТЗ, а цена последующих ТЗ снижается согласно таблице тарифов:
| Количество ТЗ | < 1000 ТЗ | < 3000 ТЗ | < 5000 ТЗ | < 10000 ТЗ | >= 10000 ТЗ |
|---|---|---|---|---|---|
| Стоимость, руб. | 0,07 | 0,05 | 0,04 | 0,03 | 0,02 |
Первые 50 запросов — бесплатные.
Приведем несколько примеров расчета бюджета парсинга частотностей:
| Исходные параметры | Количество фраз | ||||
|---|---|---|---|---|---|
| 200 | 2000 | 4000 | 8000 | 15000 | |
| 1 регион, 1 тип соответствия | 14 | 120 | 210 | 340 | 500 |
| 1 регион, 2 типа соответствия | 28 | 210 | 340 | 520 | 800 |
| 1 регион, 4 типа соответствия | 56 | 340 | 520 | 840 | 1400 |
| 5 регионов (без разделения по регионам в отчете), 4 типа соответствия | 56 | 340 | 520 | 840 | 1400 |
| 5 регионов (с разделением по регионам в отчете), 4 типа соответствия | 210 | 1000 | 1800 | 3400 | 6200 |
По сравнению с конкурентами стоимость парсинга в PromoPult в 2-3 раза ниже, особенно если речь идет о проверке большого массива ключей.
Парсер Вордстат — это лишь один из инструментов PromoPult. В разделе «Профессиональные инструменты» вы найдете чекер позиций в Яндексе и Google, парсер мета-тегов и заголовков, кластеризатор, подборщик поисковых подсказок и фраз-ассоциаций, генератор объявлений из YML, нормализатор и комбинатор слов, оптимизатор видео. Большинство инструментов полностью бесплатные.
Работа с Парсером Wordstat: помните о сезонности
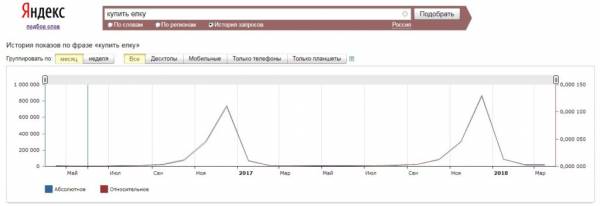
Вордстат выдает статистику за последние 30 дней. Поэтому если по запросу наблюдается сезонный спрос, то полученные данные могут быть завышенными или заниженными. Если вы видите в отчете Парсера нули и подозреваете, что со статистикой что-то не так, перейдите в Вордстат и посмотрите «Историю запросов». Ярко выраженная сезонность будет видна на графике:
Подводим итоги
Парсер Wordstat от PromoPult — это простой инструмент для быстрой проверки частотности по заданному списку фраз. Инструмент работает «в облаке», не требует создания специальных аккаунтов в Яндексе, ввода капчи, работы через прокси и других манипуляций. Выгодно выделяет инструмент возможность парсинга сразу по нескольким регионам и получения отчета с региональной разбивкой. Результаты проверки сохраняются в интерфейсе системы. Стоит парсинг в 2-3 раза дешевле, чем у конкурентов.
Хотите попробовать парсинг в действии? В системе доступно 50 пробных бесплатных проверок!
Источник: blog.promopult.ru