На сегодняшний день уже многие SEO-специалисты признают, что индексируемость сайта имеет решающее значение для увеличения органического трафика. Они делают все возможное, чтобы оптимизировать краулинговый бюджет, и получают огромное удовольствие от роста посещаемости сайта ботом Google. Однако наш случай говорит об обратном.
В июне 2020 года к нам обратился клиент с весьма необычной проблемой: Google стал крайне активно краулить его интернет-магазин. Обычно владельцы сайтов радуются, когда увеличивается краулинговый бюджет на сайте, но в данном случае сервер был перегружен и сайт практически перестал работать.
Первый вопрос, который принято задавать в подобных ситуациях: что меняли на сайте? Но клиент уверил, что никаких изменений не было.
Первичный анализ и наши действия
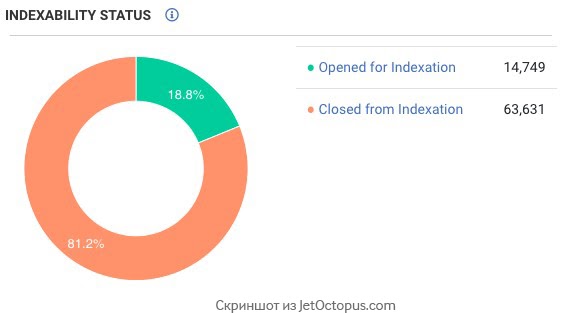
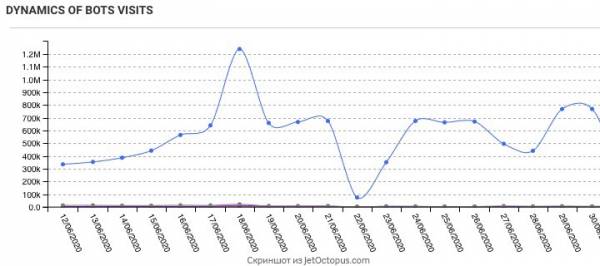
Первым делом мы сделали краул сайта. И очень удивились – на сайте меньше 100 тыс. страниц, 80 % которых закрыто от индексации. При этом Googlebot краулил в среднем 500 тыс. страниц в сутки!
Сам сайт состоит из двух частей: интернет-магазина и форума. Обычно подозрения падают в первую очередь на форум, но в данном случае он работал корректно.
Взглянув в логи, мы обратили внимание на страницы с параметром PageSpeed=noscript.
Сопоставили данные – оказалось, что на такие страницы было сделано больше 8 млн запросов от Googlebot. Очевидно, что это не нормальные URL, которые должен генерировать сайт.
Мы добавили в robots.txt Disallow: *PageSpeed=noscript* – это частично решило проблему, но бот все равно сканировал много лишних страниц.
Дальнейший анализ показал, что бот ходит по пересечениям фасетных фильтров, которые генерируют практически бесконечное количество страниц. Такие URL не были заблокированы в robots.txt, а на странице находится тег

Это еще больше усугубляло ситуацию.
В итоге мы добавили еще строчку в robots.txt Disallow: *?*.
Количество запросов от Googlebot снизилось, сайт вернулся к нормальной работе.
У нас появилось время заняться анализом причины этой ситуации.
Поиски причины
В компьютерных системах ничего не ломается само по себе, всегда есть причина. Она может быть не очевидна, часто бывает сложная цепочка причин. Но суть работы компьютера в том, что если у него есть задача взять X, прибавить к нему Y и поместить это в Z, он будет это делать практически бесконечное количество времени.
В случае с нашим кейсом клиент утверждал, что никаких изменений или действий на сайте не выполнял. Из практики мы знаем, что у разных людей разное понимание слов «мы ничего не делали», но в нашем случае это было действительно так.
Мы решили подойти с другой стороны – изучить поведение Googlebot. За последние несколько лет было не так много изменений, о которых говорилось публично. Основные – это обновление версии Chrome внутри бота и переход на evergreen.
Изначально наше внимание привлекли параметры PageSpeed=noscript в URL. Их генерирует mod pagespeed, для Apache и Nginx в случае, когда у клиента отключен JS. Этот модуль предназначен для оптимизации страниц и был весьма популярен несколько лет назад. На данный момент целесообразность его использования под вопросом.
Давайте еще раз посмотрим на скриншот из GSC:
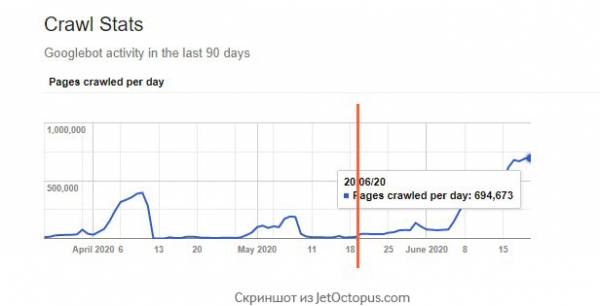
Последний скачок, который начался в районе 20 мая, привел к колоссальному росту краулинга ботом.
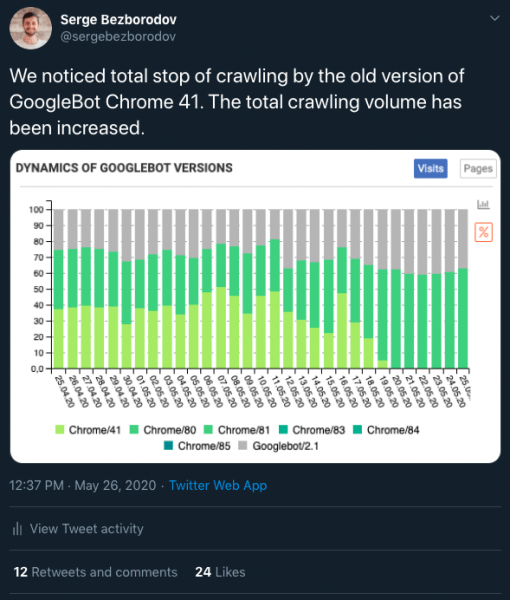
И тут мы вспоминаем, что 19-20 мая произошло отключение старого Chrome/41 внутри Googlebot.
Является ли это причиной этой ситуации? Нельзя сказать на 100 %, т. к. у нас нет исторических клиентских логов за май, которые бы могли полностью прояснить ситуацию. Но скорее всего, именно обновление Chrome внутри Googlebot могло привести к краулингу большого количества ненужных страниц, которые в старой версии не обрабатывались.
Так что же делать?
Проанализировав этот кейс, можно сделать несколько выводов:
Cобирайте логи. Это в дальнейшем может очень помочь в поиске проблем и анализе сайта. Современные хранилища весьма дешевы, можно складывать данные даже в Dropbox стоимостью 10 USD/mo за 2 ТБ данных. Если же у вас большой сайт с огромными объемами трафика, напомните вашему devops про Amazon Glacier, где за те же 10 USD/mo можно хранить 25 TБ данных. Поверьте, этого хватит на многие годы.
Источник: seonews.ru